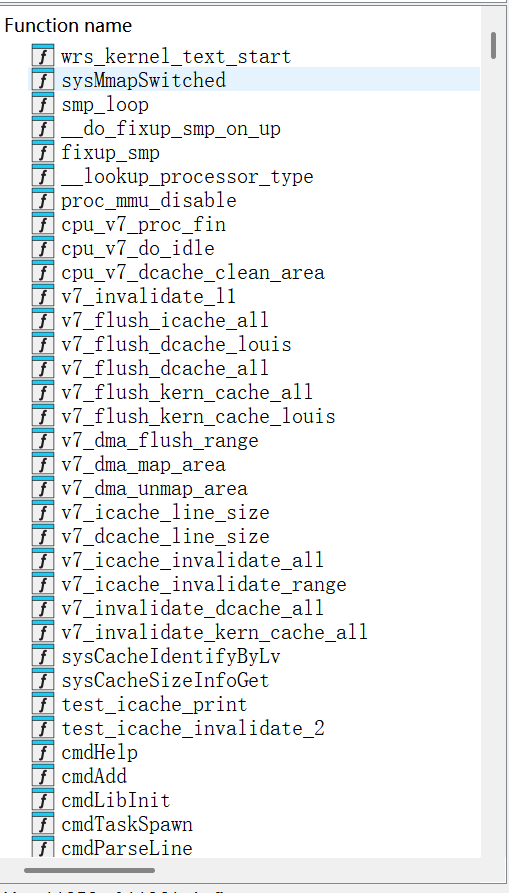
学习文章来源于[RTOS] 基于VxWorks的TP-Link路由器固件的通用解压与修复思路 – 赤道企鹅的博客 | Eqqie Blog
固件来源
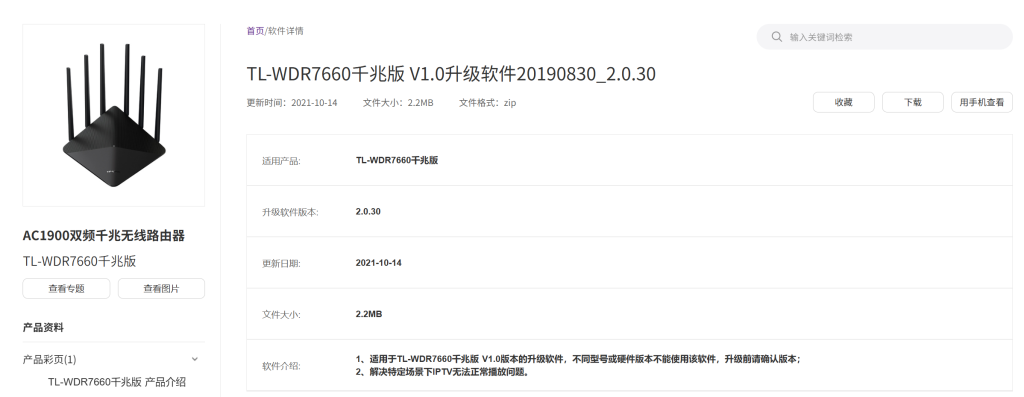
传送门:TL-WDR7660千兆版 V1.0升级软件20190830_2.0.30
固件提取
binwalk看一下
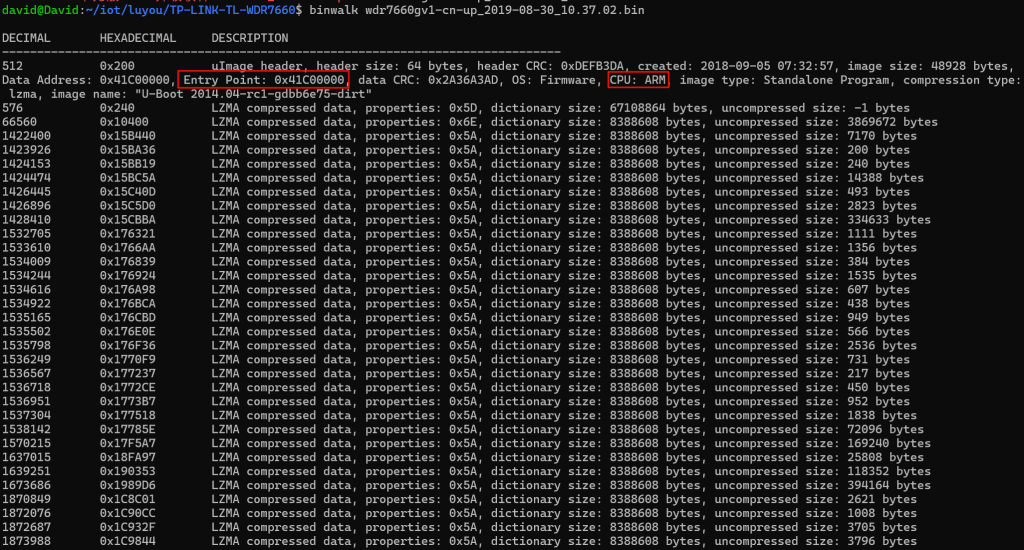
有很多LZMA格式的数据,所谓LZMA,简单理解就是压缩后的数据块,像这种没有识别到文件系统,而是一堆LZMA格式的数据块,就是RTOS架构
同时我们可以看到,这个固件是ARM架构的固件,还有一个Entry Point:0x41C00000,这个Entry Point通常来说是uBoot程序的入口,而不是我们要分析的主程序的入口
提取uBoot
uBoot通常由uImage header和紧随其后的一块LZMA compressed data组成,先要将他们提取出来:
dd if=wdr7660gv1-cn-up_2019-08-30_10.37.02.bin of=uboot.raw bs=1 skip=512 count=66048skip为起始位置,count为总大小(uImage header+LZMA compressed data = 66560 – 512)

提取主程序
在0x10400偏移也就是uImage header之后的第二块LZMA compressed data的位置存放了1.3M左右特别大的数据,一般来说这也是主程序所在,将其用同样的方法提取出来…

lzma -d ./data_0x10400.lzma提取出来解压时有一些问题
010打开固件程序,定位到0x15B440附近
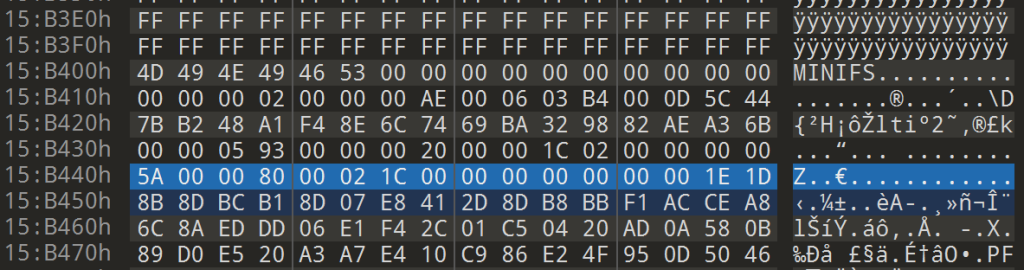
一般来说,文件末尾后面会有一堆0xff,但是很显然这个地方是一些有用的数据,而前面刚好有一堆0xff,往上回溯一下,可以发现有一堆0xff,找到0xff的起始
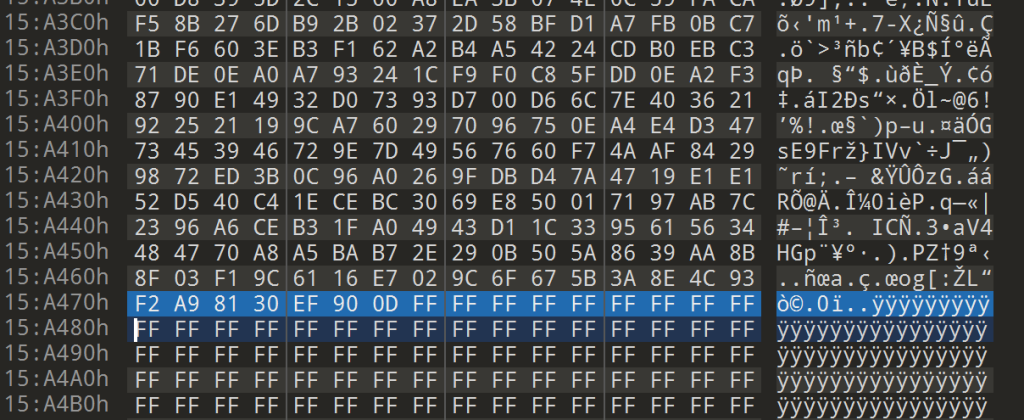
所以猜测真正的结束地址是0x15a477,于是将count修改为0x15a477 – 66560大小后再次提取
dd if=wdr7660gv1-cn-up_2019-08-30_10.37.02.bin of=data_0x10400.lzma bs=1 skip=66560 count=1351799
lzma -d ./data_0x10400.lzma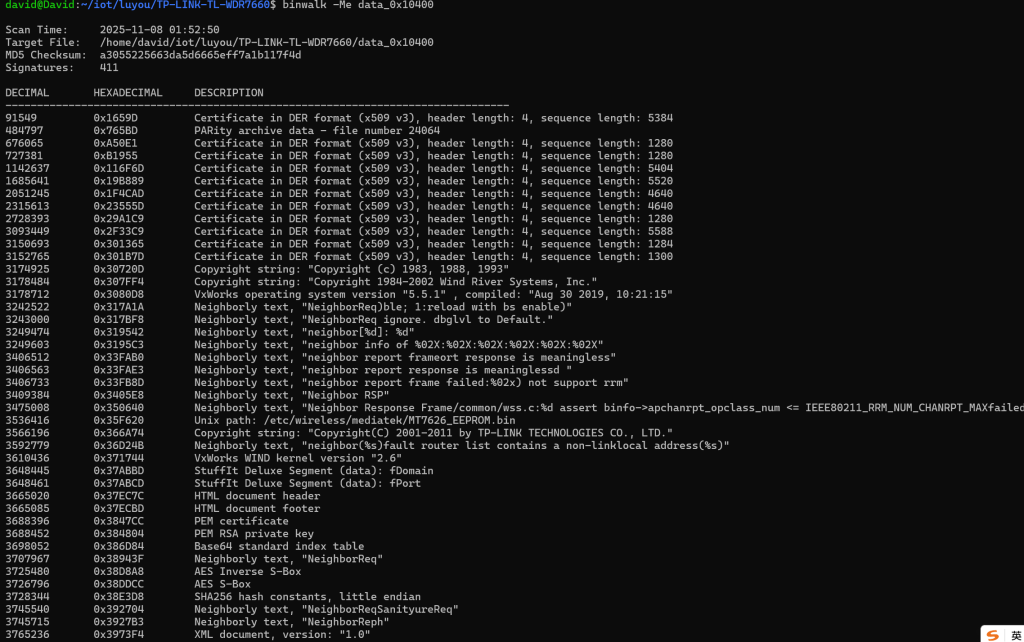
来自AI的分析:
你正在对 TP-LINK TL-WDR7660 路由器固件的一个片段
data_0x10400进行分析,使用了binwalk -Me(递归提取嵌入的文件系统/数据)。从 binwalk 的输出可以看出以下关键信息:
🔍 关键发现摘要
1. 操作系统识别
- VxWorks 5.5.1text编辑
VxWorks operating system version "5.5.1", compiled: "Aug 30 2019, 10:21:15"
- 这是 Wind River 公司开发的实时操作系统(RTOS),常见于嵌入式设备如路由器、工业控制器等。
- 同时检测到 WIND kernel version “2.6”。
2. 证书与密钥
- 多个 X.509 DER 格式证书(共 11 处)
- 一处 PEM 格式的 RSA 私钥:text编辑
3688452 0x384804 PEM RSA private key⚠️ 安全风险提示:如果这是设备出厂固件中包含的私钥,可能意味着所有同型号设备共享同一密钥,存在严重的安全漏洞(例如中间人攻击、伪造固件等)。3. 硬件与驱动线索
- 路径
/etc/wireless/mediatek/MT7626_EEPROM.bin表明使用 联发科(MediaTek)MT7626 芯片组。- 另一个路径
/etc/Wireless/RT2860/RT2860_2G.dat指向 Ralink RT2860 驱动配置(Ralink 已被 MediaTek 收购,两者技术融合)。4. 网络功能相关字符串
- 大量
"NeighborReq"、"Neighbor report"等文本,表明支持 IEEE 802.11k(无线邻居报告,用于漫游优化)。- 出现
IEEE80211_RRM_NUM_CHANRPT_MAX,进一步确认 Radio Resource Management (RRM) 功能启用。5. 其他技术细节
- 存在 AES S-Box / Inverse S-Box、SHA256 常量表、CRC32 表 → 设备支持加密与校验。
- HTML 片段(可能为 Web 管理界面的一部分)。
- XML 文档(可能是配置文件模板)。
- StuffIt 数据段(可能是压缩资源或误报,但较罕见于嵌入式 Linux/VxWorks)。
6. 版权信息
- TP-LINK 版权:
Copyright(C) 2001-2011 by TP-LINK TECHNOLOGIES CO., LTD.- Wind River 版权:
Copyright 1984-2002 Wind River Systems, Inc.
确定程序入口
这一步直接搬来师傅的结论
入口地址存放的大致规律:
首先从主程序偏移往前找,在这个例子里面就是0x10400往前
在这个范围内搜索如下字符串:MyFirmware
从字符串的偏移往上一点会发现两个重复的地址,猜测这就是主程序的加载地址和入口
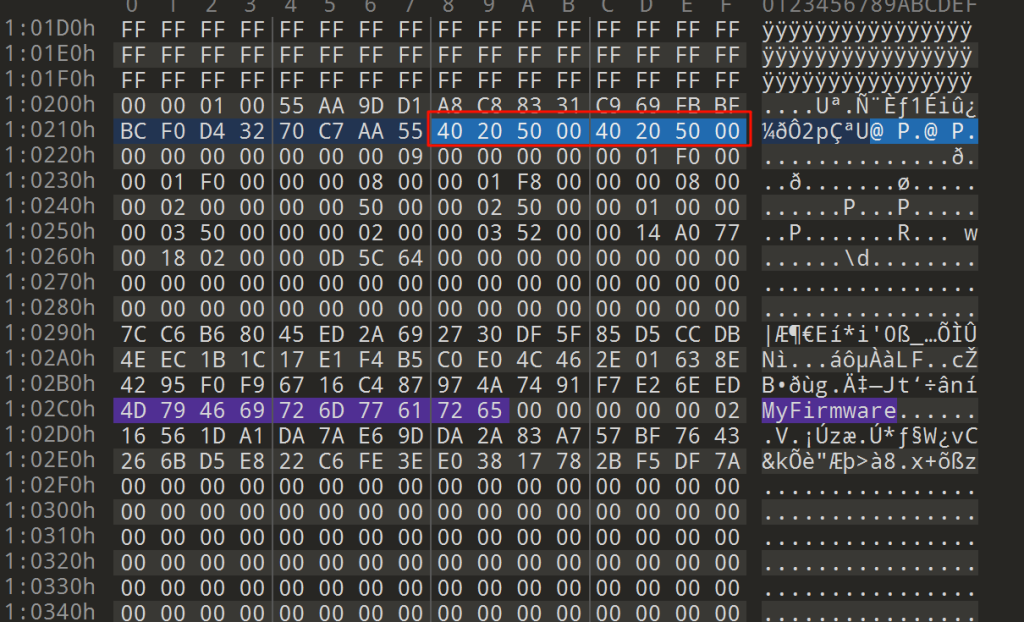
所以在这里是0x40205000
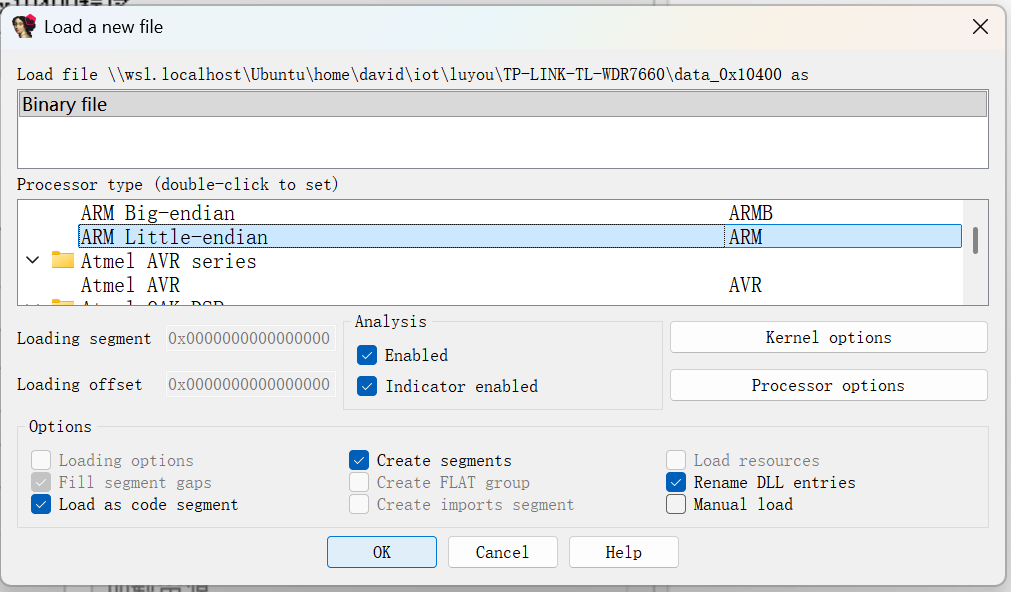
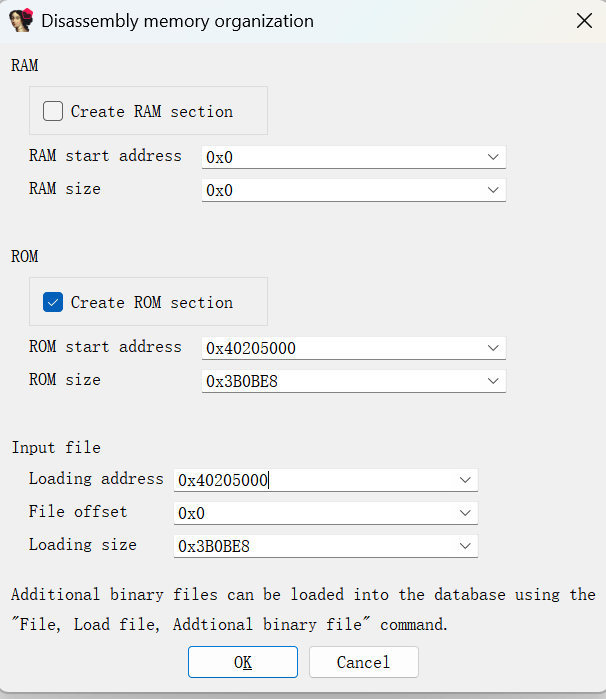
另一种方法是,首先确定程序架构是ARM32位little

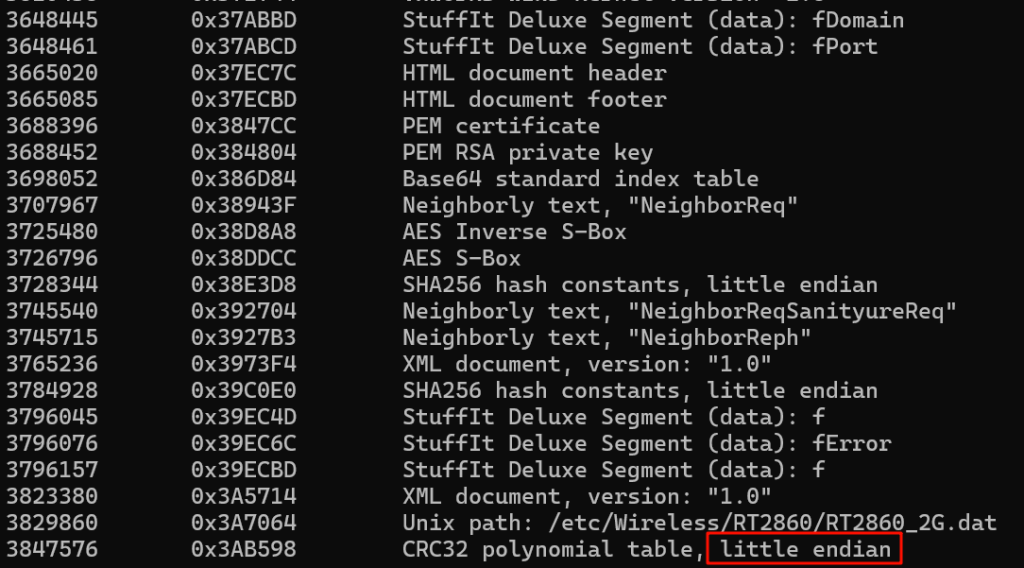
至于到底是32位还是64位,试一下便知,64位反汇编不出正常指令
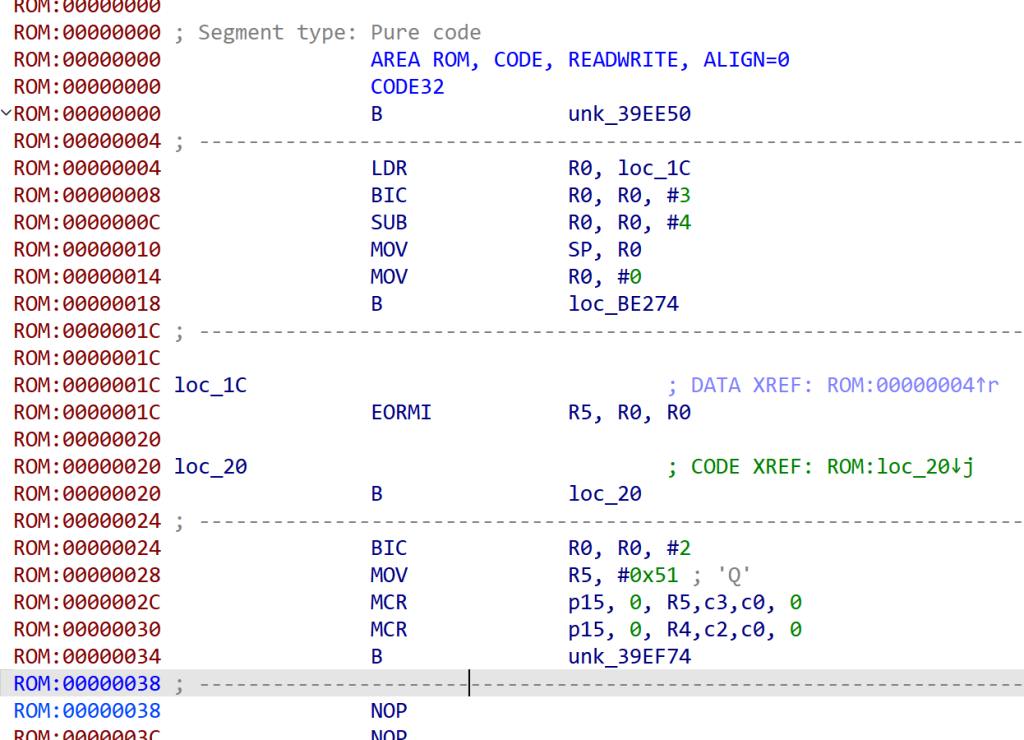
VxWorks系统的加载基址与栈初始化地址相同,根据VxWorks官方给出的说明,其采用usrInit进行栈初始化,而usrInit是VxWorks系统引导后运行的第一个函数,因此可以直接把VxWorks系统文件丢到ida中,先用0作为加载基址,然后找sp寄存器首次出现的位置,就是VxWorks系统的加载基址。

发现”LDR R0, =0x40205000”,后面接着”MOV SP, R0”,可以确定加载基址为0x40205000。
一开始没有直接显示0x40205000是因为我把这个地址按了下“c”,解析成代码了
来自AI:
1.
LDR指令(Load Register)
功能
从内存中加载一个 32 位字(word)到寄存器。
基本语法
armasm编辑
LDR Rt, [Rn, #offset] ; 从地址 (Rn + offset) 处读取 4 字节到 Rt
常见形式
| 形式 | 示例 | 说明 |
|---|---|---|
| 直接寻址 | LDR R0, [R1] | 从 R1 指向的地址读取数据到 R0 |
| 带偏移 | LDR R0, [R1, #4] | 从 R1+4 地址读取 |
| 前索引(写回) | LDR R0, [R1, #4]! | 先加偏移,再读取,并将 R1 更新为 R1+4 |
| 后索引 | LDR R0, [R1], #4 | 先读取 R1 地址的数据,再将 R1 += 4 |
| PC 相对寻址 | LDR R0, [PC, #8] | 从当前指令 + 8 字节处读取(常用于文字池) |
| 伪指令(加载立即数) | LDR R0, =0x40205000 | 汇编器自动处理,把常量放入文字池并生成 LDR |
注意:
LDR加载的是 32 位字(little-endian 默认),地址必须 4 字节对齐(否则可能触发异常或未定义行为)。
示例
armasm编辑
LDR R0, =0x12345678 ; 伪指令:R0 ← 0x12345678 LDR R1, [R2] ; R1 ← *(uint32_t*)R2 LDR R3, [R4, #8] ; R3 ← *(uint32_t*)(R4 + 8)
2.
BIC指令(Bit Clear)
功能
对寄存器进行 按位与非(AND NOT) 操作,用于清除某些特定位。
基本语法
armasm编辑
BIC Rd, Rn, Operand2
等价于:
c编辑
Rd = Rn & (~Operand2);
操作数(Operand2)
可以是:
- 立即数(需符合 ARM 立即数规则,如
#0xFF,#3)- 寄存器(如
R1)- 带移位的寄存器(如
R1, LSL #2)
经典用途:地址对齐
armasm编辑
BIC R0, R0, #3
#3的二进制是0b11~3是...11111100- 所以
R0 & ~3会清零最低两位,使地址 4 字节对齐
符号表恢复
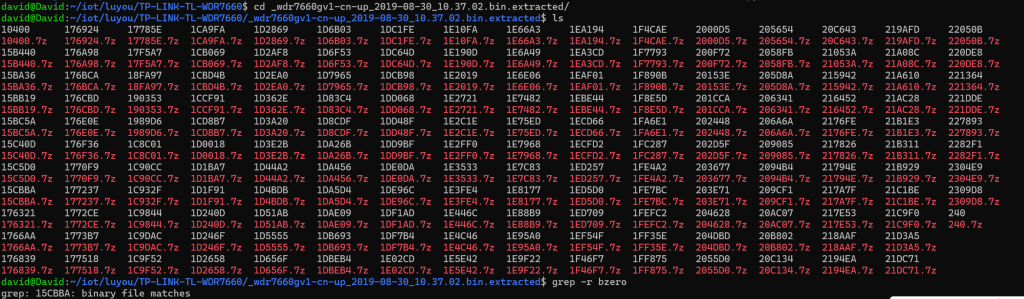
TP-LINK WDR7660的符号表和VxWorks系统文件是分离的,所以需要从binwalk解压升级文件后得到的文件中寻找符号文件。Bzero是VxWorks中一个函数,系统启动过程中会使用bzero函数对bss区的数据进行清零,因此可以利用”
”查找bzero函数,找到一个文件,很明显就是符号表所在文件了。
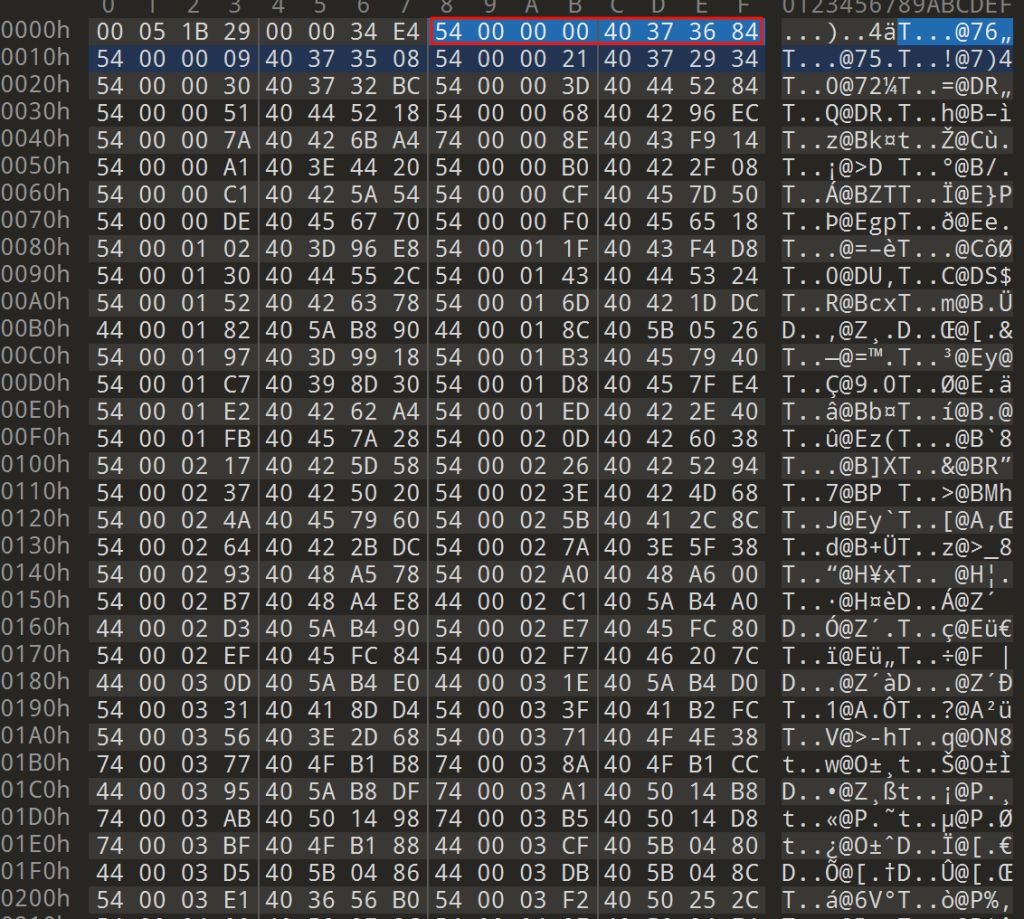
找到符号文件后,可以看出符号表的位置是从0x08到0x1a728,符号字符串的起始位置是0x1a728。
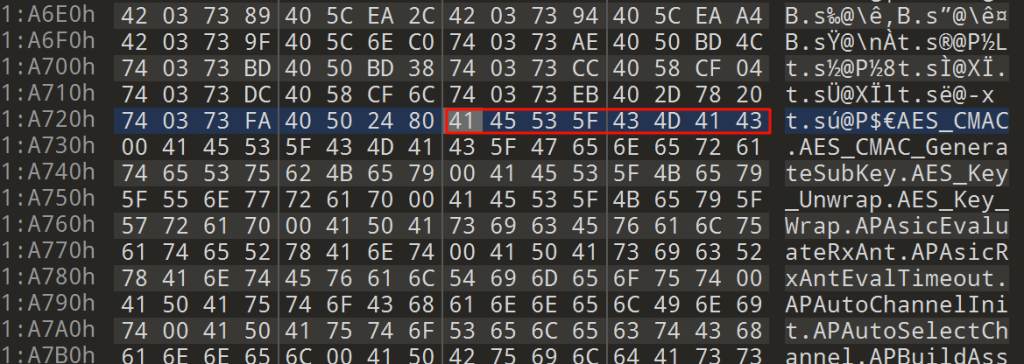
经过分析,得出符号文件中符号的存储规则如下:每8字节为一组,以54 00 00 00 40 37 36 84为例,54表示符号的类型(54表示函数名),00 00 00 表示符号在字符串表中的偏移,40 37 36 84表示符号对象在内存中的绝对地址。
常见的 flag 值(来自 ELF 或 VxWorks 风格):
0x54('T'):Text(代码,函数)0x44('D'):Data(已初始化全局变量)0x42('B'):BSS(未初始化全局变量)0x64('d'):调试符号
随便找一个函数验证一下
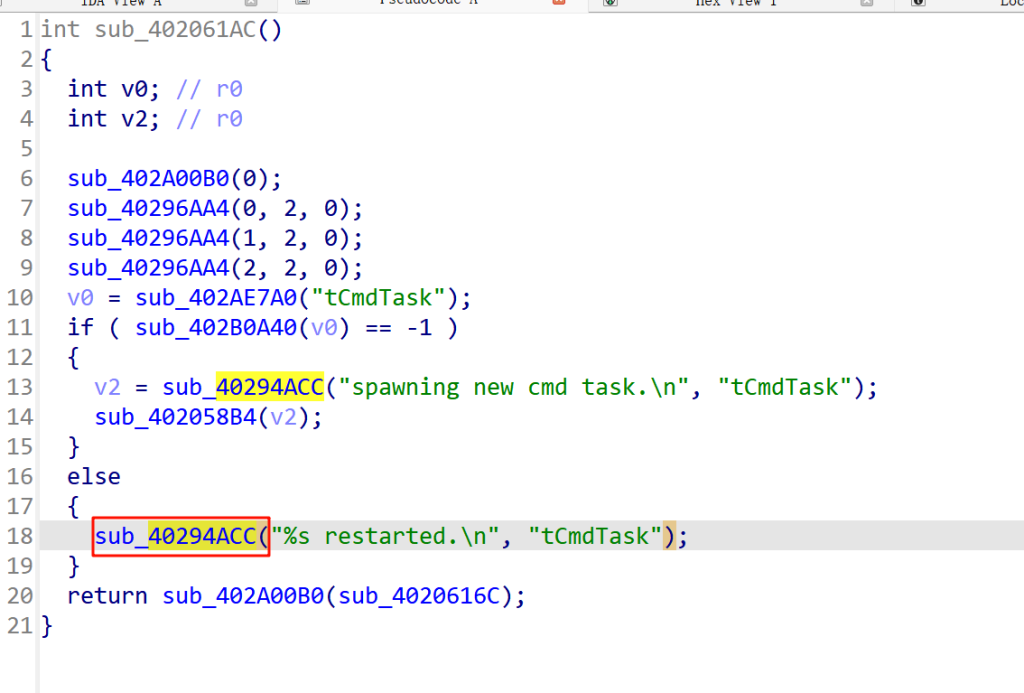
直觉告诉我们这个函数是printf函数
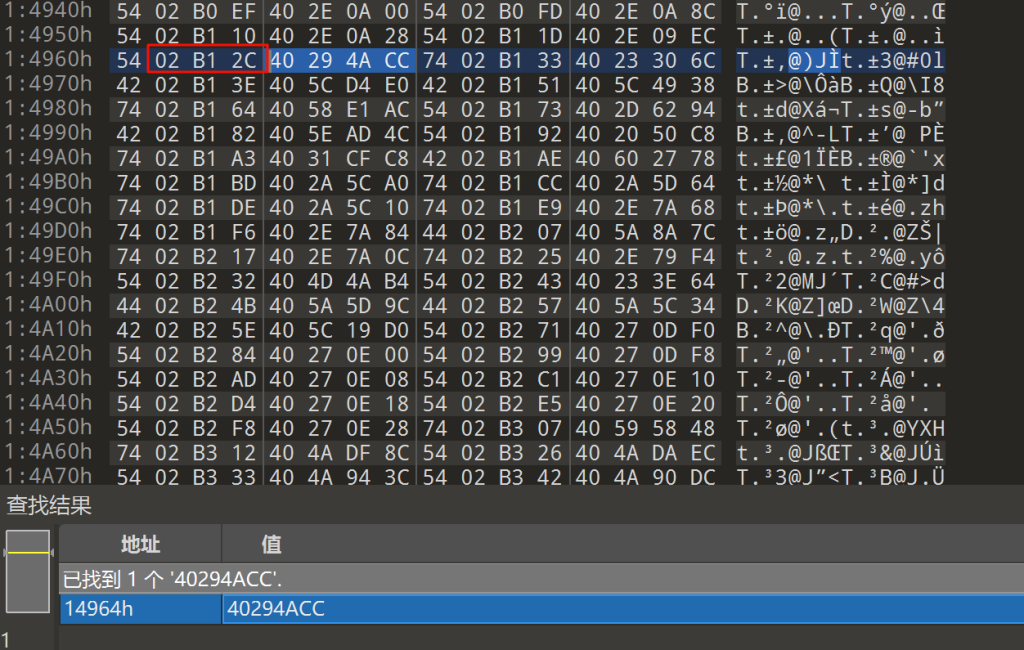
经过搜索可以得知他的字符串偏移为0x2B12C
计算0x1a728+0x2B12C=0x45854,在对应位置果然发现了printf
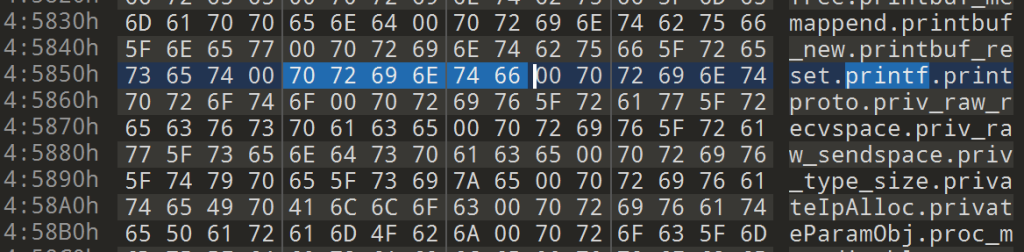
利用如下脚本可以恢复符号表
import idaapi
import idc
import ida_bytes
import ida_funcs
import struct
# ==================== 配置区 ====================
SYM_FILE_PATH = './sym_table'
SYMBOLS_TABLE_START = 8
STRINGS_TABLE_START = 0x1a728
# 架构字节序:
# '>' → Big-Endian (MIPS, PowerPC)
# '<' → Little-Endian (ARM, x86)
ENDIAN = '>' # MT7621 是 MIPS 大端
# ==============================================
def get_string_from_table(strings_data, offset):
"""从字符串表中安全读取以 \\x00 结尾的字符串"""
if offset >= len(strings_data):
return "<invalid_offset>"
end = strings_data.find(b'\x00', offset)
raw = strings_data[offset:end] if end != -1 else strings_data[offset:]
try:
return raw.decode('utf-8', errors='replace')
except Exception:
return repr(raw)
def parse_symbol_entry(entry, strings_data):
"""
解析 8 字节符号项:
[1B flag][3B str_off][4B addr]
"""
flag = entry[0]
# 手动解析 3 字节 string offset(大端或小端)
if ENDIAN == '>':
str_off = (entry[1] << 16) | (entry[2] << 8) | entry[3]
else:
str_off = entry[1] | (entry[2] << 8) | (entry[3] << 16)
# 解析 4 字节地址
addr = struct.unpack(ENDIAN + 'I', entry[4:8])[0]
name = get_string_from_table(strings_data, str_off)
return flag, name, addr
def make_function_at(ea):
"""在地址 ea 强制创建函数"""
if ida_funcs.get_func(ea):
return True # 已存在
# 清除可能的数据定义
ida_bytes.del_items(ea, ida_bytes.DELIT_SIMPLE)
# 创建第一条指令
if not idc.create_insn(ea):
print(f"[-] create_insn failed at {ea:#x}")
return False
# 创建函数
if not ida_funcs.add_func(ea):
print(f"[-] add_func failed at {ea:#x}")
return False
return True
def main():
try:
with open(SYM_FILE_PATH, 'rb') as f:
data = f.read()
except Exception as e:
print(f"[!] Failed to open symbol file: {e}")
return
if SYMBOLS_TABLE_START >= len(data) or STRINGS_TABLE_START >= len(data):
print("[!] Invalid symbol table offsets!")
return
symbols_raw = data[SYMBOLS_TABLE_START:STRINGS_TABLE_START]
strings_raw = data[STRINGS_TABLE_START:]
symbols = []
entry_size = 8
for i in range(0, len(symbols_raw), entry_size):
if i + entry_size > len(symbols_raw):
break
entry = symbols_raw[i:i+entry_size]
try:
flag, name, addr = parse_symbol_entry(entry, strings_raw)
symbols.append((flag, name, addr))
except Exception as e:
print(f"[!] Parse error at offset {i}: {e}")
continue
print(f"[+] Parsed {len(symbols)} symbol entries.")
applied_names = 0
created_funcs = 0
for flag, name, addr in symbols:
if addr == 0 or not idaapi.is_loaded(addr):
continue
# 设置名称(即使不是函数也设名)
if idaapi.set_name(addr, name, idaapi.SN_NOWARN | idaapi.SN_NOCHECK):
applied_names += 1
# 如果是代码符号(0x54 = 'T')
if flag == 0x54:
if make_function_at(addr):
created_funcs += 1
print(f"[+] Applied {applied_names} names, created {created_funcs} functions.")
print("[+] Symbol loading completed.")
# ==================== 入口 ====================
if __name__ == "__main__":
main()适配于ida9.0,我还将其做成了插件,但是还在测试适配性和通用性,等测试没问题了在发出来吧~